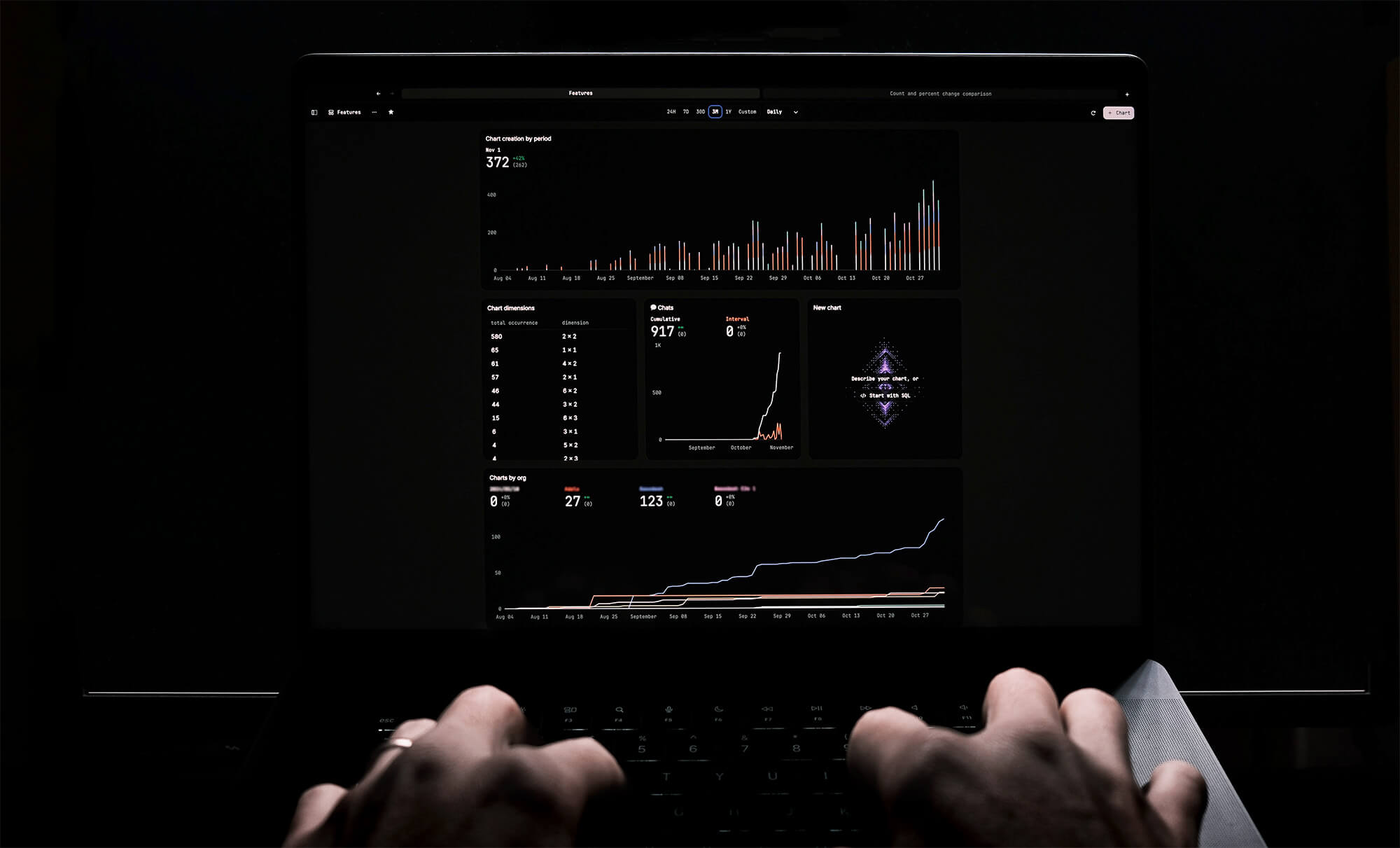
It’s time to stop mocking data

There aren’t many designers out there who would advocate for working with less or no information about the product they’re building. We want to know who is using our product, what their motivations are, what kind of frustrations they might have, what work environment are they in, and what other tools they are using to accomplish a task.
We need data to do our jobs effectively. We have analytics, we have KPIs, sure, but we’re faking the rest. We’re designing interfaces, experiences, and services that are all built on data that isn’t even real. We’re idealizing product compositions, filling them with stock images and Lorem Ipsum, and hoping and praying that people will use our products the way that they exist in a Figma document.
Let me define what data I’m talking about for a second:
Digital products are scaffolds for user data. One easy example is the product information that might exist on an ecommerce website:
What does the product image look like?
Does it have a white background?
Does the product have a description, variants, colors, different shipping options?
What products are related to it?
What are the reviews for the product?
Who makes it? What does their logo look like?
What other information do we have about it? Size? Weight? Number of boxes? Return policy? New versions? And on and on and on.
Product designers have to guess at what information exists, or what will exist. What names products will use, how long those names will be, how they’ll be categorized, what metadata exists, etc.

We can observe, test, interview, and “mock” the data, but we are always removed from the actual thing. Sure, we can copy and paste things from a Google search, or look around for something similar, but most of the time we don’t have access to the real, actual guts of our product.
Why?
Well, most of the time it’s a security risk to see that information for anyone but a developer. The more people that have credentials, the more at risk your organization.
If that’s not the issue, then it’s usually too hard or not important enough to figure out a way for team members to get access to it. After all, it’s not a great use of a developer’s time to play crossing guard and get data for everyone. From my experience, it’s like pulling teeth to get a CSV of actual data from a database to reference, and then there’s no way to make changes to it, correct it, or see what other relationships are built on it.

Why do developers hold the keys to that information?
Why can’t the rest of the product team know what data is inside of their products?
Why is it so hard to see what information your product is built around?
Now, before I go further, all data is not equal. I don’t think that anyone should have access to things like users’ social security number, password, address, medical history, or really any data that is personally identifiable. Those types of data are standard, and can be auto-generated without needing to be real.
I'm talking about the other types of data that are business-specific or non-generic. Things that are wholly unique but not identifiable and not a security risk.
That data is a goldmine for ideas and better products. It tells you how people are working in your system vs what they are saying. It tells you how complex your product categorization really is, or shows you metadata that you capture but never thought to expose to customers to help with their buying experience.

When designing a product, working with guessed data vs with real data will have dramatically different outcomes.
At Basedash, I use Basedash to figure out how Basedash is used to design better ways to use Basedash. Meta.
I don't have access to our users’ databases or personal information (and again, we take great lengths to protect and secure any and all connection points to our product) but I can learn from the way they use and bend it to meet their needs. For example:
How do they title their views?
How many people are on a team?
How many of them have profile pictures?
What do they call their data sources?
Who’s using vs creating in our tool?
How many people are using a specific feature?
What types of custom roles are people defining?
None of these details individually shape a feature, but together, and in tandem with other research, they paint me a more complete picture.
For example:
In Basedash, we currently don’t have a way for people to categorize or reorder views. To inform the solution, I looked at our how people were naming them.
I saw some called “Active Users”, “Shipments in transit”, and “Workspace invitations”.
To be expected.
But I also saw:
“Bob - TEST - A - Active Users”
“DO NOT TOUCH - Customer Support”
“Operations - Test”
“🔥 Leads (live)” and “🔥 Leads (not live)”
“Untitled view”
“Untitled view”
and the infamous “Copy of Untitled view”.
The workarounds reframed my mindset to see that people were not only struggling with categorization, they were using naming conventions to solve:
- Sorting
- Access
- Tagging
- Filters
- Sharing
- Permissions
- Environments
- Testing ideas
- Team structure
- And many more
Folders (my first idea and a user request) would help, but only to a certain point. This problem was bigger than categorization. This was bigger than just losing track of things.
By having access to product data I was able to change my rationale and design work on what was real. There are a mountain of plugins out there that help with mocking data, but there is no replacement for the real thing.
Real data is messy, full to typos, copies, miscategorizations, and old information. Looking through it tells a story and allows you to reframe other research and feature requests. No workspace will ever be perfectly organized, tagged, and tidy—but for the first time in my career, I can now build solutions that help users make better sense of their real work without needing to navigate an API, pull teeth for credentials, or rely on out-of-date CSVs exported in 2014.
Invite only
We're building the next generation of data visualization.