Our TypeScript monorepo setup
Robert Cooper ![]() Robert Cooper Senior Engineer at Basedash
· April 7, 2023
Robert Cooper Senior Engineer at Basedash
· April 7, 2023

Robert Cooper ![]() Robert Cooper Senior Engineer at Basedash
· April 7, 2023
Robert Cooper Senior Engineer at Basedash
· April 7, 2023
Our Basedash app is set up as a TypeScript monorepo. That means that our client (React app) and our server (node.js app) both live in the same repository. We like the monorepo approach because it makes it easy to make changes between the server and client in one pull request, simplifies our deployments, and makes code sharing between client and server more manageable. This article is going to go over the following details:
tsconfig.json file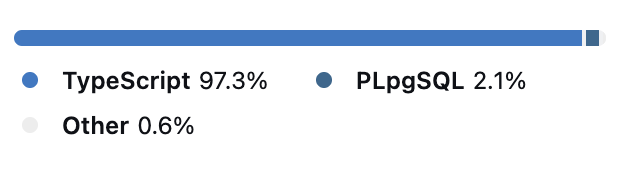
Breakdown of the languages used in our monorepo. Can you tell we love TypeScript?
Here’s a simplified overview of how our monorepo code is structured.
apps/
client/
server/
packages/
constants/
eslint-config-basedash/
prisma/
types/
utils/
e2e/
package.jsonprisma package instead of keeping it within the server app directory is because we use the generated Prisma types on both the client, server, and other shared packages. This is especially useful for Prisma enums.eslint-config-basedash)package.json contains information about how all the code is related and it contains scripts used to run Turborepo tasksYarn workspaces is how we manage to share code between our apps and packages. Here’s a look at the package.json in the root of the monorepo where we specify the Yarn workspace config:
{
"private": true,
"workspaces": {
"packages": [
"apps/*",
"packages/*"
],
"nohoist": [
"**/jest",
"**/prisma",
"**/@prisma/client"
]
}
}The private option must be set to true since it is a requirement for yarn workspaces. The nohoist is required to get Prisma and Jest working properly where it is used within the underlying packages and apps. You can read more about what nohoist does here.
For each package in our packages directory, there is a package.json file where the name of the package is specified. For example, our constants package has a name of @basedash/constants:
{
"name": "@basedash/constants"
}All our package names start with @basedash/ except for our eslint config which is named eslint-config-basedash. This is because ESLint requires that shareable config names are prefixed by eslint-config- (docs on shareable ESLint configs).
In order to use a package within an app or another package, the package needs to be specified in the consuming app’s/package’s package.json as a dependency (or devDependency) with * as the version (which means “match any version”).
As an example, our client app references all the packages as well as the server by having the following in its package.json:
{
"dependencies": {
"@basedash/constants": "*",
"@basedash/types": "*",
"@basedash/utils": "*",
"@basedash/prisma": "*",
"@basedash/server": "*"
}
}Then in a .tsx file in the client, we can import stuff as we normally would for any other npm package:
import { SOCKET_EVENTS } from '@basedash/constants';Each package and app needs to have its own tsconfig.json file in order to use TypeScript files. We have a root tsconfig.json file at the root of the monorepo that has default TypeScript configuration options use by all of our packages and apps. Each package and app extends from the root tsconfig.json file and can specify additional TypeScript configuration options.
Here is our root tsconfig.json file:
{
"compilerOptions": {
"target": "es6",
"strict": true,
"noUncheckedIndexedAccess": true,
"lib": ["ES2019", "ES2021.String"],
"esModuleInterop": true,
"allowJs": true,
"allowSyntheticDefaultImports": true,
"moduleResolution": "node",
"module": "commonjs",
"resolveJsonModule": true,
"skipLibCheck": true,
"isolatedModules": true,
"declaration": true
},
"exclude": []
}And here’s how one of our packages (e.g. our constants package) can extend from the root tsconfig.json file:
{
"extends": "../../tsconfig.json",
"compilerOptions": {
"outDir": "dist",
"rootDir": ".",
},
"include": [
"**/*.ts"
]
}With a common shared config, we can more easily maintain consistency of code in our TypeScript monorepo without needing to duplicate configuration options.
As mentioned earlier, we have a shared ESLint package named eslint-config-basedash and each app and package extends from this shared ESLint config by having the following in each app’s/package’s .eslintrc file:
{
"root": true,
"extends": [
"basedash"
]
}This allows for all our code to use a common set of ESLint rules, while still allowing for additional customizations on a per-app or per-package basis.
Here’s how the .eslintrc file looks like in our server app directory:
{
"root": true,
"extends": ["basedash"],
"rules": {
"no-restricted-imports": ["error", {
"name": "utils/logger",
"importNames": ["logger"],
"message": "Use the logger instance on req.logger since it holds information like the user's ID and email"
}],
"no-console": "error"
}
}The server’s ESLint config adds custom ESLint rules that throw errors if there are any usages of console.log or if someone tries to import the logger from utils/logger.
We are using tRPC for most of our API endpoints (in tRPC lingo, endpoints are defined as procedures). This allows us to make API calls via the tRPC client, which ensures that all the passed arguments are properly type-checked and that the data received from the API is also fully typed. Because our tRPC procedures are defined in our server app directory, we are required to transpile/build our server code in order to allow our client app to use the generated tRPC types.
The flow looks as follows:
client appThe client app uses the tRPC server types as follows:
import type { TrpcRouter } from '@basedash/server';
import { createTRPCProxyClient, httpBatchLink } from '@trpc/client';
export const trpcClient = createTRPCProxyClient<TrpcRouter>({
links: [
httpBatchLink({
url: `/trpc`,
}),
],
});TrpcRouter is a type exported from the server app that contains all the typing corresponding to the tRPC API endpoints/procedures.
export type TrpcRouter = typeof appRouter;Where appRouter is the tRPC router on which all the endpoints/procedures are defined.
One thing to note about tRPC is that it incorporates well with superjson, which allows you to send stuff like Date objects or Map and Set objects from your server and have them still represented as Dates, Maps, and Sets on the client. Normally, if you don’t use a tool like superjson to serialize and deserialize your API payloads, your Date objects will be converted to strings because you can’t send Date objects via HTTP requests.
We tried using superjson, but found that we were having to manually convert most of our Date objects to strings anyways in order for them to be stored in our Redux store (see Redux docs on avoiding non-serializable values). Therefore, we use tRPC without superjson.
We use Turborepo to build our apps and packages as well as run other “tasks” in our apps and packages, such as linting, testing, and typechecking.
Here’s a look at our turbo.json config file:
{
"pipeline": {
"build": {
"outputs": [
"dist/**",
"build/**"
],
"dependsOn": [
"^build"
]
},
"test": {
"outputs": [],
"dependsOn": []
},
"lint": {
"dependsOn": [],
"outputs": []
},
"typecheck": {
"dependsOn": [],
"outputs": []
},
"clean": {
"cache": false
}
}
}And here are the scripts defined in the root package.json that are used to run the Turborepo tasks:
{
"scripts": {
"build": "turbo run build",
"build:packages": "turbo run build --filter=@basedash/* --filter=!@basedash/client",
"lint": "turbo run lint",
"test": "turbo run test",
"clean": "turbo run clean && rm -rf node_modules",
"typecheck": "turbo run typecheck"
},
"devDependencies": {
"turbo": "^1.2.9"
}
}Here’s an explanation of each of our tasks:
client app, builds the optimized/minified HTML and JavaScript files used for a web app.tscnode_modules directories as well as any build outputs (i.e. dist or build directories). Used when debugging things and needing to start from a clean slate.The way tasks work is that when a task is run, such as turbo run lint, Turborepo will go through all the lint commands specified in the scripts of each package’s package.json file. Also, as long as "cache": false isn’t specified in the turbo.json config for the task, then Turborepo will cache the result of running the task for each package. This means that if turbo run lint is ran twice in a row without making any changes to the files in the yarn workspace packages, then Turborepo will simply use the same lint result found from the cache.
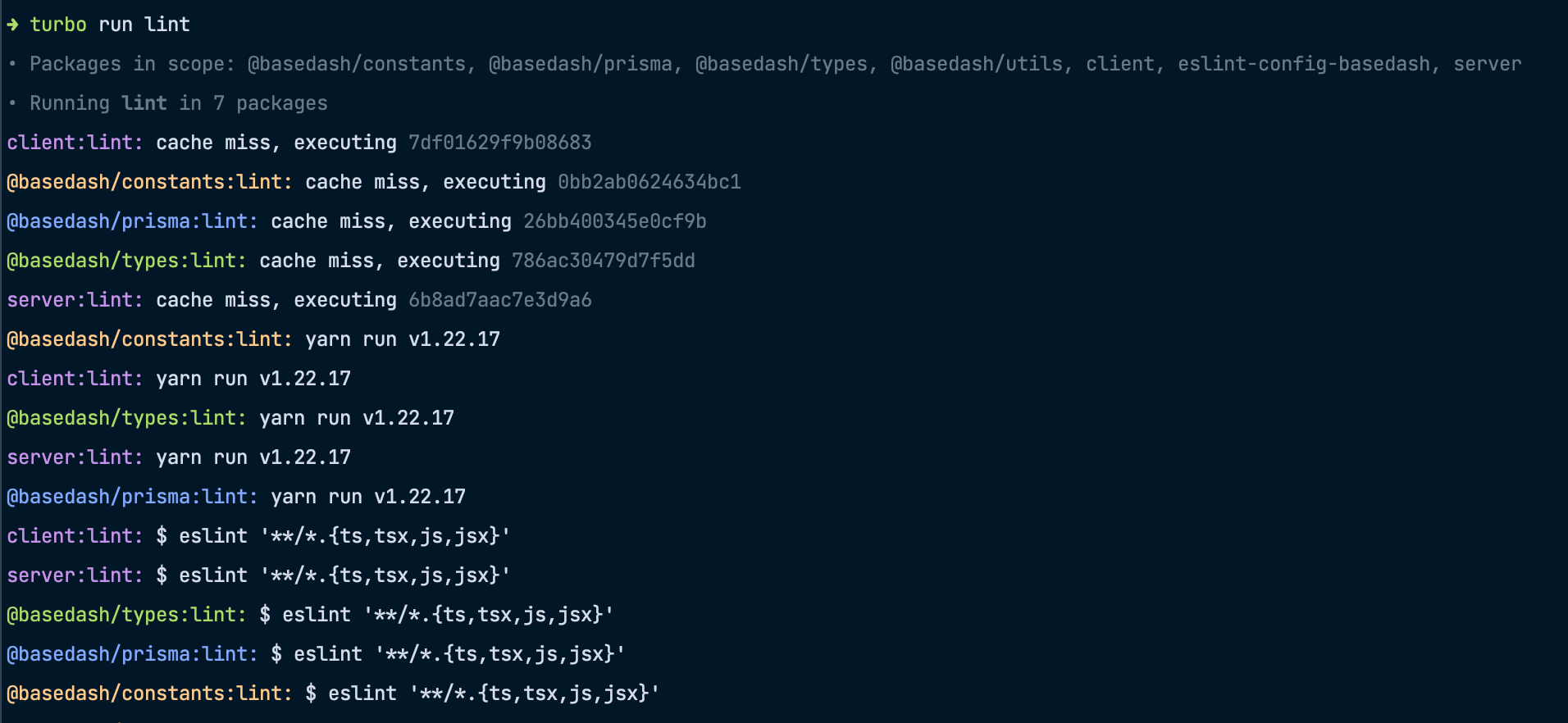
Here’s an example of a portion of the output shown as a result of running turbo run lint for the first time. Notice how turbo repo says “cache miss”, indicating that it doesn’t have anything to read from the cache.
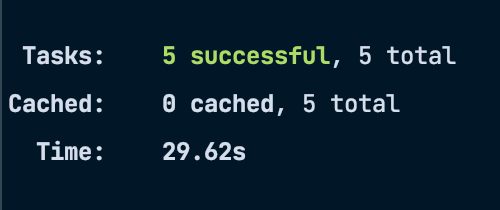
It took 29.62s to run the lint task on our monorepo. Now if turbo run lint is ran again, turborepo will notice that no files have changed, so it will “replay” the output and not run the lint command for each package again (turbo repo calls this “full turbo” when everything is cached).
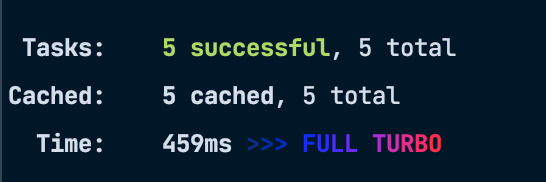
This is most noticeable for us when running turbo run build since building our packages is what takes the longest amount of time in our CI. Now, if we make a pull request that only affects code in the client app, then Turborepo will only build the client app and get the builds for all the other packages from a remote cache. To get remote caching setup, see Turborepo’s documentation page.
The great thing about this is that the remote caching also works within docker, which is important for us since when we are building our packages on our CI, we do so within docker. Here’s the line/instruction in our Dockerfile that runs the Turborepo build task:
RUN yarn build --token=$TURBO_TOKEN --team=$TURBO_TEAMThe token and team arguments are ultimately read from environment variables configured on our CI that specify where the Turborepo remote cache is found.
Before Turborepo, the best we could do with caching our docker builds was to enable Docker Layer Caching on CircleCI (our CI provider). Docker Layer Caching caches the results of running instructions in your Dockerfile, but when it reached the RUN yarn build instruction (prior to turborepo), it would only read from the docker cache if ALL the files in ANY of the packages/apps haven’t been modified. This is of course not useful since it’s highly likely that when making a code change in our monorepo, we will have changed code in one of our packages (the only exception being if the code change only affects end-to-end tests or CI config files). With Turborepo, we can read from the remote Turborepo cache and only build what needs to be built.
If interested, you can read more about how the docker build cache works here: https://docs.docker.com/develop/develop-images/dockerfile_best-practices/#leverage-build-cache. Read more about the turbo repo caching here: https://turbo.build/repo/docs/core-concepts/caching
One of the biggest annoyances that remains is having to always rebuild our server code when making a change to a tRPC endpoint. This could be solved if we were to migrate our app to Next.js since the server code and client code could co-exist together (i.e. wouldn’t need to be linked together via yarn workspaces). This is something we’ve been considering, but the migration from a single-page app built with parcel to a Next.js app seems daunting. That being said, some people have done it (see this Twitter thread) and it might be doable for us without too much work.
I’d also like to migrate away from yarn and instead use pnpm. I sometimes get some strange issues with installing packages using yarn and pnpm seems to be faster and the latest gold standard for package managers. We’ve tried to migrate once already but ran into some blockers.
Here’s a Twitter thread summarizing the main points of the article:
1/7: Basedash uses a TypeScript monorepo setup for efficient code sharing and builds between client and server.
2/7: The monorepo structure consists of “apps”, “packages”, and “e2e”.
3/7: Code sharing is managed through yarn workspaces, which allows for easy reference to shared packages.
4/7: Shared TypeScript configuration options are maintained using a common tsconfig.json file.
5/7: We use a shared ESLint package and extend it for customizations on a per-app or per-package basis.
6/7: Type-safe APIs are created via tRPC, which ensures all passed arguments are properly type-checked.
7/7: Turborepo is used to build apps and packages and run tasks such as linting, testing, and typechecking, with the ability to cache results.
Written by

Senior Engineer at Basedash
Robert Cooper is a senior engineer at Basedash who builds full-stack product systems across SQL data infrastructure, APIs, and frontend architecture. His work focuses on application performance, developer velocity, and reliable self-hosted workflows that make data operations easier for teams at scale.
Basedash lets you build charts, dashboards, and reports in seconds using all your data.